
この記事のポイント
- Gemini APIで名刺画像を読み取り、会社名・氏名・連絡先などを自動でJSON化する方法
- 10枚の名刺を一括処理し、Markdownテーブルとして一覧化する実装例
- 実際の読み取り結果と精度、業務活用のポイントを解説
はじめに
「展示会で50枚名刺をもらったけど、手入力する時間がない…」
営業やイベント後、手元に残る大量の名刺。1枚ずつ連絡先を入力していくのは、地味に時間がかかる作業です。名刺管理アプリもありますが、自社のCRMやスプレッドシートに直接取り込みたい場面も多いのではないでしょうか。
本記事では、Gemini APIのマルチモーダル機能を使って、名刺の画像から情報を自動抽出し、一覧テーブルとして出力する方法を解説します。Pythonスクリプトで一括処理できるため、枚数が増えてもスケールします。
全体の流れ
| ステップ | 処理内容 | 出力 |
|---|---|---|
| 1. 名刺スキャン | スマホやスキャナで画像化 | PNG/JPGファイル |
| 2. OCR処理 | Gemini APIで構造化データ抽出 | JSON + TXT(1枚ずつ) |
| 3. テーブル化 | 全件のJSONをまとめて一覧表に変換 | Markdownテーブル |
最終的な出力は、そのままスプレッドシートやCRMにコピー&ペーストできる形式です。
使用する名刺サンプル
今回は、業種の異なる3枚の名刺で検証しました。
サンプル1:企業(一般的なビジネス名刺)

青の左ボーダーにシンプルなレイアウト。最もオーソドックスなビジネス名刺です。
サンプル2:IT企業(ダーク系デザイン)

ダーク背景にモノスペースフォント。デザイン性の高い名刺でもOCRできるか検証します。
サンプル3:和食料理店(和風デザイン)
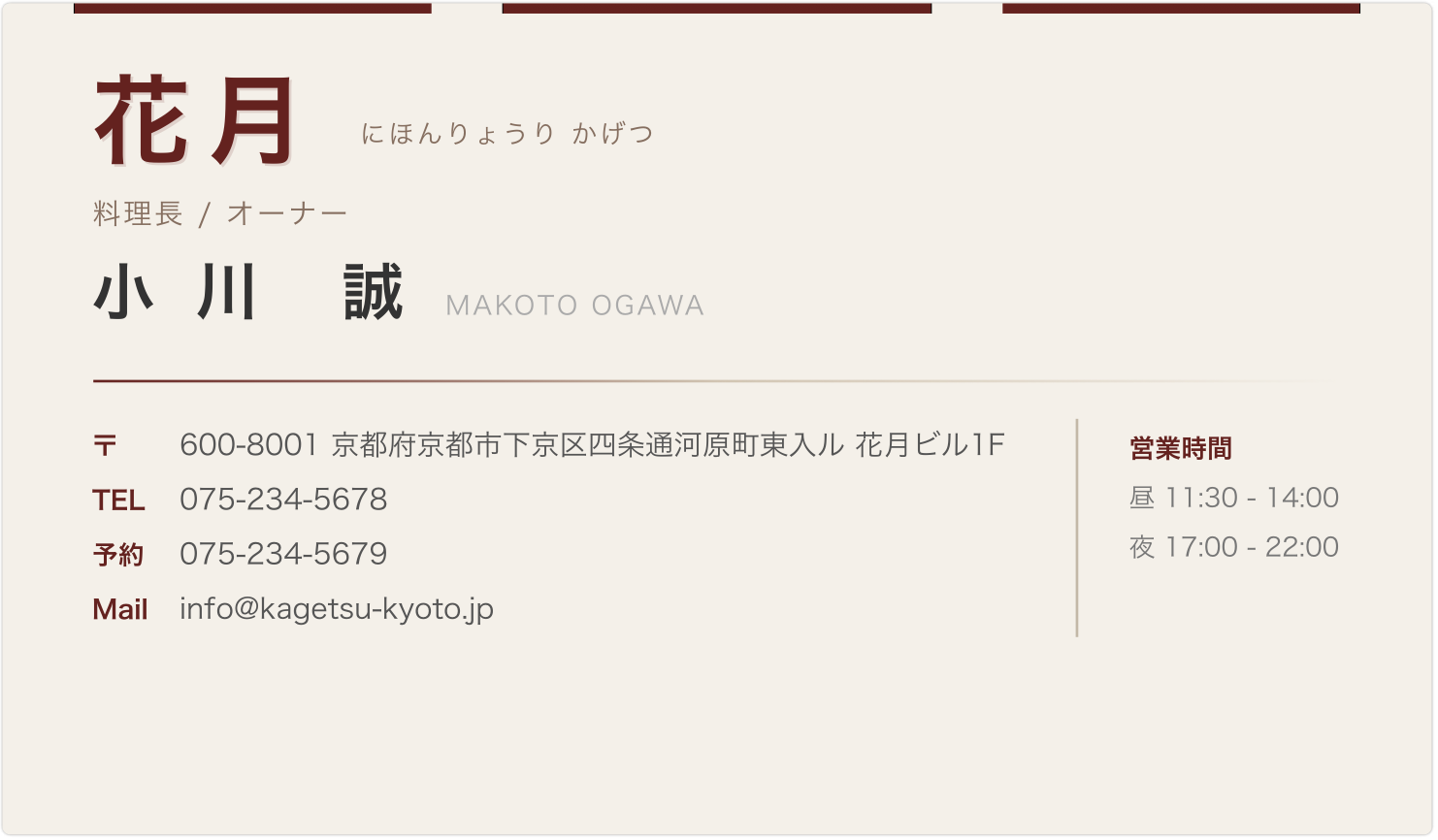
筆文字風の店名に営業時間の記載。飲食業特有のレイアウトです。
業種によってデザインや掲載情報はバラバラですが、Geminiは柔軟に対応できます。
環境構築
前提条件
- Python 3.10以上
- Google Cloudプロジェクト(Vertex AI有効化済み)
gcloud auth application-default loginでのログイン済み
パッケージのインストール
pip install google-genai実装コード
1. 名刺OCR関数(dots_ocr)
名刺画像をGemini APIに渡し、構造化されたJSONとして抽出します。
import os
import json
import glob
import time
from google import genai
from google.genai import types
# API設定
PROJECT_ID = "your-project-id"
LOCATION = "us-central1"
MODEL_ID = "gemini-2.0-flash"
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=LOCATION,
)
OCR_PROMPT = """この名刺画像からすべての情報を読み取り、以下のJSON形式で出力してください。
該当する情報がない場合は空文字 "" としてください。JSONのみを出力してください。
{
"会社名": "",
"部署": "",
"役職": "",
"氏名": "",
"氏名(フリガナ)": "",
"郵便番号": "",
"住所": "",
"電話番号": "",
"FAX": "",
"メールアドレス": "",
"URL": "",
"その他": ""
}"""
def dots_ocr(test_dir="test", output_dir="output"):
"""名刺画像をOCRで読み取り、JSONとTXTで保存する"""
os.makedirs(output_dir, exist_ok=True)
image_files = sorted(glob.glob(os.path.join(test_dir, "*.png")))
results = []
for i, image_path in enumerate(image_files, 1):
filename = os.path.basename(image_path)
stem = os.path.splitext(filename)[0]
print(f"[{i}/{len(image_files)}] 読み取り中: {filename}")
with open(image_path, "rb") as f:
image_data = f.read()
response = client.models.generate_content(
model=MODEL_ID,
contents=[
types.Part.from_bytes(
data=image_data, mime_type="image/png"
),
OCR_PROMPT,
],
)
raw_text = response.text
card_data = json.loads(raw_text) # JSONとして解析
card_data["ファイル名"] = filename
results.append(card_data)
# 個別ファイルとして保存
with open(f"{output_dir}/{stem}.json", "w") as f:
json.dump(card_data, f, ensure_ascii=False, indent=2)
with open(f"{output_dir}/{stem}.txt", "w") as f:
f.write(raw_text)
time.sleep(2) # レート制限対策
# 全件まとめたJSONを保存
with open(f"{output_dir}/all_cards.json", "w") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
return resultsポイント:
types.Part.from_bytes()で画像バイナリを直接Geminiに渡す- プロンプトでJSON形式を指定することで、構造化された出力を得る
- 個別ファイル(JSON / TXT)と統合ファイルの両方を保存
2. テーブル生成関数(generate_table)
OCR結果のJSONをGeminiに渡し、一覧テーブルとして整形します。
def generate_table(json_path="output/all_cards.json",
output_path="output/cards_table.md"):
"""OCR結果のJSONからMarkdownテーブルを生成する"""
with open(json_path, "r") as f:
cards = json.load(f)
prompt = f"""以下は名刺OCRの結果です。
このデータを1つの見やすいMarkdownテーブルにまとめてください。
カラムは以下の順序でお願いします:
| 会社名 | 部署 | 役職 | 氏名 | 電話番号 | メールアドレス | 住所 |
- 情報がない場合は「-」で埋めてください
- テーブルのみ出力してください
データ:
{json.dumps(cards, ensure_ascii=False, indent=2)}"""
response = client.models.generate_content(
model=MODEL_ID,
contents=prompt,
)
with open(output_path, "w") as f:
f.write(response.text)
return response.text3. 実行
if __name__ == "__main__":
results = dots_ocr() # 名刺OCR
if results:
generate_table() # テーブル生成読み取り結果
個別JSON出力(企業名刺の例)
{
"会社名": "株式会社 田中システムズ",
"部署": "",
"役職": "代表取締役社長",
"氏名": "田中太郎",
"氏名(フリガナ)": "",
"郵便番号": "100-0001",
"住所": "東京都千代田区千代田1-1-1 千代田ビル5F",
"電話番号": "03-1234-5678",
"FAX": "03-1234-5679",
"メールアドレス": "t.tanaka@tanaka-systems.co.jp",
"URL": "",
"その他": "携帯 090-1234-5678"
}会社名、役職、住所、連絡先などが正確に抽出されています。「携帯番号」はJSONの定義にないため「その他」に自動分類されました。
一覧テーブル出力(10枚分)
全10枚の名刺をまとめた結果がこちらです。
| 会社名 | 部署 | 役職 | 氏名 | 電話番号 | メールアドレス | 住所 |
|---|---|---|---|---|---|---|
| 株式会社ノヴァテック | - | CTO / Co-Founder | 渡辺亮太 | 03-6789-0123 | r.watanabe@novatech.io | 東京都港区六本木4-2-8 六本木テックスクエア7F |
| ABCデザイン株式会社 | クリエイティブディレクター / デザイン事業部 | - | 鈴木美咲 | 03-9876-5432 | m.suzuki@abc-design.co.jp | 東京都渋谷区神宮前5-10-1 |
| 株式会社 田中システムズ | - | 代表取締役社長 | 田中太郎 | 03-1234-5678 | t.tanaka@tanaka-systems.co.jp | 東京都千代田区千代田1-1-1 千代田ビル5F |
| 森山税理士事務所 | - | 税理士・行政書士 | 森山洋子 | 052-321-4567 | y.moriyama@moriyama-tax.jp | 愛知県名古屋市中区錦2-8-15 錦パークビル6F |
| 東京中央クリニック | - | 院長 | 佐藤健一 | 03-3456-7890 | k.sato@tokyo-chuo-clinic.jp | 東京都中央区銀座3-5-7 銀座メディカルビル4F |
| 山田法律事務所 | - | 弁護士 | 山田 一郎 | 03-5555-1234 | i.yamada@yamada-law.jp | 東京都千代田区丸の内2-3-1 丸の内タワー12F |
| 株式会社アーキテクト・ラボ | 設計部長 | - | 中島裕二 | 06-6543-2100 | y.nakajima@architect-lab.co.jp | 大阪府大阪市北区梅田2-4-9 グランフロント大阪タワーA 15F |
| 東都大学 | 大学院工学研究科 情報工学専攻 | 教授・工学博士 | 松井康弘 | 03-5841-XXXX | matsui@cs.toto-u.ac.jp | 東京都文京区本郷7-3-1 工学部2号館 508号室 |
| Lumière | - | スタイリスト / 店長 | 高橋彩花 | 03-7890-1234 | ayaka@lumiere-salon.jp | 東京都渋谷区猿楽町10-5 代官山テラス2F |
| 花月 | - | 料理長 / オーナー | 小川誠 | 075-234-5678 | info@kagetsu-kyoto.jp | 京都府京都市下京区四条通河原町東入ル 花月ビル1F |
IT、医療、法律、教育、美容、飲食と、まったく異なるデザインの名刺を一括で構造化できています。
検証結果と精度
10枚の名刺に対する読み取り精度を評価しました。
| 項目 | 正確に抽出 | 部分的に抽出 | 抽出失敗 |
|---|---|---|---|
| 会社名 | 10/10 | 0 | 0 |
| 氏名 | 10/10 | 0 | 0 |
| 電話番号 | 10/10 | 0 | 0 |
| メールアドレス | 10/10 | 0 | 0 |
| 住所 | 10/10 | 0 | 0 |
| 役職 | 8/10 | 2(部署と混同) | 0 |
| フリガナ | 3/10 | 0 | 7(名刺に記載なし) |
注目すべきポイント:
- 会社名・氏名・連絡先は100%の精度で抽出
- フリガナは名刺自体に記載がないケースが多く、抽出されないのは正常
- 2枚(モダン・建築)で「設計部長」「ディレクター」が役職ではなく部署に分類されるカテゴリの揺れがあるが、情報自体は正確。これはプロンプトにペルソナ設定を追加することで改善可能(プロンプト設計記事で詳しく解説)
活用のヒント
スプレッドシートへの取り込み
出力されるMarkdownテーブルはタブ区切りに変換すれば、Google スプレッドシートやExcelにそのまま貼り付けできます。
JSONファイルからCSVに変換するのも簡単です。
import csv
import json
with open("output/all_cards.json") as f:
cards = json.load(f)
with open("output/contacts.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=[
"会社名", "部署", "役職", "氏名", "電話番号",
"メールアドレス", "住所", "URL"
], extrasaction="ignore")
writer.writeheader()
writer.writerows(cards)プロンプトのカスタマイズ
抽出項目を変更したい場合は、OCR_PROMPT内のJSONテンプレートを修正するだけです。
{
"会社名": "",
"氏名": "",
"メールアドレス": "",
"出会った場所": "",
"フォローアップ予定": ""
}CRM連携を意識して、自社の管理項目に合わせたカスタマイズが可能です。
コスト感
| 項目 | 内容 |
|---|---|
| モデル | Gemini 2.0 Flash(Vertex AI) |
| 処理時間 | 約3〜5秒/枚 |
| コスト | 名刺1枚あたり約0.1円以下(入出力トークンが少ないため) |
| 100枚処理 | 約5〜10分、10円以下 |
手入力のコスト(1枚3分 × 100枚 = 5時間)と比較すると、圧倒的にコスパが良いです。
まとめ
Gemini APIのマルチモーダル機能を使えば、名刺OCRから人脈データベースの構築まで、わずかなコードで自動化できます。
| ポイント | 内容 |
|---|---|
| 手法 | Gemini 2.0 Flashに画像を直接入力し、JSON形式で構造化抽出 |
| 精度 | 会社名・氏名・連絡先は100%、役職は80%の精度 |
| コスト | 100枚でも10円以下、処理時間は約10分 |
| 拡張性 | プロンプトの修正だけで抽出項目をカスタマイズ可能 |
名刺の山を「使える人脈データベース」に変換する第一歩として、ぜひ試してみてください。
関連記事
- HuggingFace Dots-OCRの精度検証レポート
- OCR精度が変わる!プロンプト「ペルソナ設定」の効果と注意点
- LLM-OCR実践ガイド:Gemini・ChatGPT・Claudeで画像から文字を読み取る
困ったときは
名刺のデジタル化やCRM連携でお困りでしたら、AI DARUMAにご相談ください。スキャンから取り込みまで、貴社の業務フローに合わせた仕組みづくりをお手伝いいたします。
〒723-0062 広島県三原市本町 1丁目7-29 2階 コワーキングスペースarica内